4月24日讯:国内大模型研发应用领域热潮持续高涨。据不完全统计,目前国内至少有19家企业及科研院所涉足人工智能大模型训练,主要分为大型科技公司、科研院校和初创科技团队三类。从大模型的布局体系来看,百度、阿里、华为等大型科技公司从算力层、平台层、模型层、应用层进行了四位一体的全面布局,科研院校及初创科技公司主要以研发大模型算法及细分领域应用为主;从大模型参数量看,大型科技公司的参数量远大于科研院所,但基本都处于千亿及以上规模;从大模型应用方向看,大部分企业前期以内部应用为主,后续主要向B端企业拓展服务,预计少数企业将在C端市场形成规模。总体来说,业界普遍认为国内大模型与GPT-3的水平相当,与GPT-4仍有较大差距。
01
我国人工智能大模型总体情况
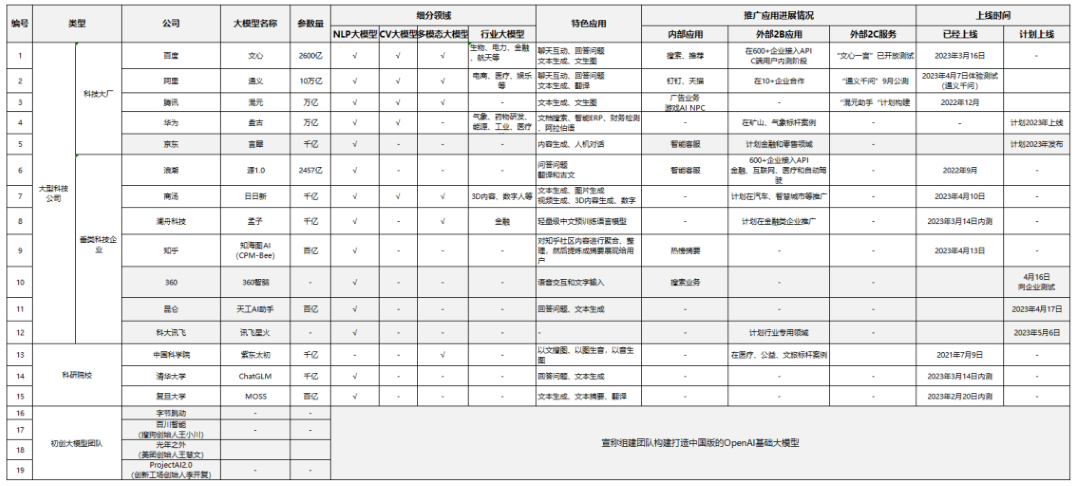
据不完全统计,截止到2023年4月20日,国内至少有19家企业及科研院所涉足人工智能大模型训练,主要分为大型科技公司、科研院校和初创科技团队三类。具体来看:百度、阿里等12家大型科技公司和中国科学院、清华大学等3家科研院校已经提供开放测试,或有明确的推出时间计划;字节跳动、搜狗创始人王小川、美团创始人王慧文、创新工场创始人李开复等则是最近对外宣布组建团队,进军大模型研发领域。其中,字节跳动旗下火山引擎于4月18日发布自研DPU(数据处理器)等系列云产品,推出新版机器学习平台,可以支持万卡级大模型训练、微秒级延迟网络,为预训练模型提供强大的算力支持。
从大模型的布局体系来看,科技大厂在算力层、平台层、模型层、应用层进行了四位一体的全面布局。百度、阿里、华为三家均从芯片到应用进行自主研发的全面布局,如百度的“昆仑芯+飞桨平台+文心大模型+行业应用”、阿里的“含光800芯片+M6-OFA底座+通义大模型+行业应用”、华为的“昇腾芯片+MindSpore框架+盘古大模型+行业应用”。垂直行业科技企业和科研院校,主要以研发大模型算法及细分领域应用为主,自有算力相对薄弱,很少涉及芯片领域自主研发。
从大模型参数量看,科技大厂的参数量远大于科研院所。科技大厂的大模型参数量较大:阿里通义千问大模型参数在10万亿级以上、腾讯混元大模型和华为盘古大模型参数量均在万亿级以上、百度文心一言大模型参数量在2千亿级以上、京东言犀大模型的参数量为千亿级;垂直行业科技企业已经上线的参数量普遍在千亿级以上;而科研院校大模型的参数量在千亿级及以下。
从大模型应用方向看,大部分企业前期以内部应用为主,后续主要向B端企业拓展服务,预计少数企业将在C端市场形成规模。目前,百度文心大模型、华为盘古大模型、中国科学院紫东太初大模型均在B端垂类市场积累了标杆应用案例,腾讯混元大模型、阿里通义大模型则更多聚焦公司自身业务。而在C端市场应用方面,百度文心一言、阿里通义千问、腾讯混元助手三类大模型最有可能向此方向拓展,但目前只有百度文心一言大模型正在进行友好客户测试,阿里通义千问大模型则计划在今年9月份进行公测,腾讯混元助手大模型则处于计划开发状态。
从大模型业界评估看,国内大模型与GPT-4有较大差距,但科技大厂具备追赶实力。目前国内大模型处于百花齐放的状态,但业界普遍认为,百度、阿里巴巴、腾讯、华为四家在大模型研发投入、技术能力和人才团队等方面综合实力较强;商用推进方面,四家企业均依托现有业务领域更容易形成大模型应用规模效应。
表1 中国人工智能大模型主要厂商情况表
02
典型企业的大模型发展情况
针对全面布局的百度、阿里、华为、腾讯四家公司,以及垂直领域入局的商汤公司的进一步分析,发现各家企业在大模型领域探索路径各有特色。
(一) 百度文心大模型:早布局,内外双向发力
1、总体概况
百度是国内领先布局AI领域的科技大厂,也是我国最早发布知识增强大语言模型产品的企业。2010年,百度成立了人工智能自然语言处理部,是中国最早布局AI的企业之一。据百度披露,其在AI领域累计投入研发总额超过千亿元,专利数量连续五年居全国第一。早在2019年,百度就发布文心大模型ERNIE(以下简称文心大模型),目前已迭代至千亿级参数的ERNIE 3.0 Zeus。2023年3月,百度相继发布了知识增强大语言模型产品“文心一言”和企业级产品“文心千帆”,可以为多个行业提供API接口及相应的开发工具链。
百度以“昆仑芯+飞桨平台+文心大模型+行业应用”在算力层、平台层、模型层、应用层具备完整布局。
在算力层,算力基础设施均由百度智算中心支持,昆仑芯二代(百度持股70%)已广泛应用在文心大模型,预计昆仑芯三代将于2024年初量产;在平台层,百度飞桨PaddlePaddle是其自主研发的深度学习平台,文心大模型通过百度飞桨平台,实现模型训练、推理部署和场景应用;该平台对外部535万开发者提供EasyDL、BML等开发工具和各种API;在模型层,文心大模型具备自然语言处理、计算机视觉、多模态以及生物计算四大类能力;在应用层,文心大模型将应用在电力、燃气、金融、生物医药、航天、传媒、城市、影视、制造、社科等多个行业。
2、市场应用和推广情况
百度文心大模型积极拓展内外部应用,目前面向公众和企业用户同时进行开放测试。内部应用层面,文心大模型已经率先应用于百度搜索、信息流、智能驾驶、百度地图、小度智能屏等内部重要产品上;外部应用层面,文心大模型在金融、能源、制造、城市、传媒、互联网等行业有标杆应用案例,实现真实场景应用的同时获取大量行业数据反哺大模型的优化。据媒体公开信息显示,目前600多家企业宣布加入文心大模型生态。
3、内外部评估情况
百度CEO李彦宏在3月对外宣称,文心一言和GPT-3版本相差一两个月的时间。目前文心一言是业界唯一一个对大众用户开放测试的知识增强大语言模型产品,根据研究团队最新测试,文心一言的文本生成能力较强,针对3月份业界质疑的“文生图不达中文意境”的问题已经进行了修正,但仍存在常识性错误、“一本正经地胡编乱造”等现象。
(二)阿里通义大模型:建生态,率先内部应用
1、总体概况阿里以“含光800芯片+M6-OFA底座+通义大模型+行业应用”成为大模型全部环节的重要参与者。2019年,阿里达摩院开启大模型研究。2022年9月,阿里正式发布通义大模型,包括通义M6多模态模型、通义AliceMind自然语言处理模型、通义视觉计算机视觉模型。2022年11月,阿里推出AI开源社区“魔搭”(ModelScope),旨在打造下一代“模型即服务”的共享平台,整合业界多方模型提供者,为开发者提供预训练基础模型和API接口。目前该平台已有超过300个开源模型,包括阿里自有的通义大模型系列以及澜舟科技孟子系列模型等外部资源和能力。2023年4月,阿里正式发布了“通义千问”产品,该产品基于10万亿级参数的大模型底座M6-OFA,未来将具有多轮交互及复杂指令理解、可多模态融合、支持外部增强API等多种能力。另外,阿里不仅拥有最多的英伟达A100芯片,还拥有自研芯片含光800、倚天710芯片,共同为人工智能大模型提供算力。
2、市场应用和推广情况通义大模型将全面支撑阿里系所有产品。目前阿里通义大模型主要定向邀请企业用户测试,尚未向公众客户开放。内部应用层面,阿里已宣布旗下所有产品未来将全面改造接入通义大模型,包括天猫、钉钉、高德地图、淘宝、优酷、盒马等;外部应用层面,阿里通义大模型目前正探索与OPPO、太平洋保险、吉利汽车电子等企业,在电子、金融、汽车等领域开展合作。
3、内外部评估情况根据对阿里专家的调研,通义千问大模型主要偏向文本,但目前还不具备图片、视频生成能力;在预训练语料数据集方面,其质量和规模上都逊于Open AI和百度,总体相当于GPT-3,与百度文心一言效果相近。而外部业界测试显示,通义千问大模型在文字创作领域,尤其在语言翻译领域表现较为出色,但在复杂理科计算方面仍有提升空间。
(三)华为盘古大模型:全栈式服务,深耕行业应用
1、总体概况华为打造了“昇腾芯片+MindSpore框架+盘古大模型+行业应用”四位一体的完整体系,主要面向企业市场提供全栈式服务。2020年,华为启动研发盘古大模型。2021年4月,华为正式发布盘古大模型,包括自然语言处理、计算机视觉、科学计算等大模型。其中,盘古自然语言处理大模型可应用于智能文档搜索、智能 ERP、小语种大模型等领域;盘古计算机视觉大模型则聚焦分类、分割、检测等视觉场景,可应用于工业质检领域;科学计算大模型则主要用于解决各种科学问题,如气象预报、海浪预测等。另外,华为盘古大模型依托自研的昇腾910、920系列芯片,与MindSpore框架形成一个整体,为企业提供全栈式的应用服务。
2、市场应用和推广情况据华为公开信息显示,盘古大模型在能源、零售、金融、工业、医疗、环境、物流等100多个行业完成场景验证。但截止2023年4月16日,华为云官网尚未显示盘古大模型上线状态。
3、内外部评估情况据华为公开信息显示,在医药领域,利用盘古药物分子大模型让先导药的研发周期从数年缩短至一个月,研发成本降低70%;在气象领域,依托盘古气象大模型,可提供秒级全球气象预报,预测速度提高万倍以上,台风轨迹预测准确度世界第一,相比欧洲气象局提升约20%;在工业领域,盘古机器视觉大模型使样本筛选效率提升约30倍,筛选质量提升约5倍,开发成本降低90%。另外,外部评估暂无最新信息。
(四)腾讯混元大模型:练内功,高度适配自有业务
1、总体概况腾讯构建了“太极机器学习平台+混元大模型”,同时腾讯启动了“混元助手”知识增强大语言模型项目。2016年,腾讯成立了AI Lab实验室。2022年4月,腾讯对外披露了混元大模型,涉及自然语言处理、计算机视觉、多模态等多个领域。腾讯自研的太极机器学习平台为混元大模型提供算力,可支持10TB级模型训练、TB级模型推理计算能力等。另据媒体报道,2023年3月,腾讯对标ChatGPT已成立“混元助手”战略级项目组。
2、市场应用和推广情况混元大模型目前主要服务于腾讯内部业务。截止2023年4月16日,腾讯混元大模型尚未对企业和公众客户开放测试。内部应用层面,混元大模型已成功应用于腾讯广告,将全面接入微信端、QQ端和王者荣耀、英雄联盟游戏端,提供智能聊天、内容推荐、情感分析、故事生成、角色塑造等功能;外部应用层面,业界推测腾讯混元大模型将在游戏、社交、金融、教育、医疗等领域发展生态,但腾讯尚未公开其明确的行业应用方向。
3、内外部评估情况据腾讯公开信息显示,混元大模型精准地把广告投放给特定人群,相比以前的小模型算法,腾讯混元大模型已累计给广告主带来15%的GMV提升。另外,外部评估暂无最新信息。
(五)商汤日日新大模型:目标成为通用人工智能新基建
1、总体概况商汤以“AI大装置SenseCore算力平台+新SenseNova大模型”为企业提供模型训练基地。2018年,商汤启动大模型研究。2022年,商汤推出了320亿参数量的通用视觉模型,在自动驾驶、工业质检、医疗影像等多个领域落地应用。2023年4月,商汤发布大模型“日日新SenseNova”,推出自然语言处理、内容生成、自动化数据标注、自定义模型训练、模型研发功能等多种能力。另外,商汤的AI大装置“SenseCore”是亚洲最大的算力平台之一,可以同时支持 20个千亿级参数的大模型训练,最高可支持万亿参数超大模型的训练。
2、市场应用和推广情况日日新大模型目前已面向政企客户开放测试。在应用层面,根据其官方网站显示,该模型计划支持智能汽车、智慧生活、智慧商业、智慧城市等业务板块。

